

The question costing enterprises millions in failed AI projects is not which model to pick — it’s why they’re asking the wrong question entirely. A CIO/CTO-level analysis of GPT-4o, Claude Sonnet 4.6, Gemini 1.5 Pro, Mistral Large, and LLaMA 3 70B: where each wins, where each breaks, and how to build a system that uses all of them intelligently.
01 — THE STRATEGIC MISSTEP
Your Model Selection Process Is Broken
Every week, we see the same pattern play out inside enterprise AI teams. A Head of AI spends six weeks running benchmarks across three models. Procurement joins the conversation. A vendor pilot kicks off with a 90-day timeline and a $150K consulting engagement attached. Somewhere at the end of it, the team picks a model — and files it under “AI strategy.”
It isn’t strategy. Model selection is a procurement decision dressed up as a strategic one. And in 2026, with over 140 frontier models publicly available and benchmark scores converging to within a few percentage points of each other, it is also increasingly irrelevant as a competitive differentiator.
The CIO who spent Q1 debating GPT-4o vs. Claude Sonnet 4.6 is playing the wrong game. Their competitor didn’t pick a better model — they built a better system.
| “The biggest mistake enterprises make is asking: ‘Which LLM is best?’ — instead of: ‘Which architecture should we build?’ Model performance converges. System architecture diverges. The enterprise that wins isn’t the one that picked Claude over GPT — it’s the one that engineered a routing layer that deploys each model precisely where it outperforms the alternatives.“ |
That said, you still need to understand what each model actually does under real enterprise constraints. Not at the benchmark level — at the production failure mode level. At 10 million token calls per month. At 500ms latency budgets. In regulated industries where a hallucinated clause in a contract isn’t an inconvenience, it’s a liability.
02 — 2026 MARKET REALITY
Surface Parity, Deep Divergence
| 140+ Frontier models publicly available in 2026 | <8% Average benchmark gap across top-5 models on general tasks | 12× Cost variance between cheapest and priciest per equivalent task |
The headline benchmarks — MMLU, HumanEval, MATH, GPQA — have compressed dramatically. The top five models are within a rounding error of each other on general-purpose tasks. If you’re choosing a model based on leaderboard rankings alone, you’re optimizing for something that correlates weakly with production value.
The real differentiation happens at the constraint boundary. When your documents are 200K tokens long. When your latency requirement is under 800ms. When your legal team has decided that hallucinations carry direct liability. When your EU data protection officer needs to approve the deployment architecture before go-live.
What Actually Changed in 2025–2026
1. Multimodality became table stakes, not a premium: Voice, vision, and structured output are now baseline expectations. The question is no longer whether a model handles images — it’s how gracefully it degrades when modality combinations create edge cases in production.
2. Context windows exploded — and created new failure modes: Gemini’s 1M+ token context is genuinely transformative for long-document workloads. But “lost in the middle” attention degradation is a real production problem that benchmarks don’t surface.
3. Open-weight models closed the quality gap at the 70B parameter range. LLaMA 3 70B is performing tasks in 2026 that would have required a frontier API call in 2024. For enterprises with MLOps capability, the total cost of ownership math has fundamentally changed.
“The model you choose is less important than the layer you put around it — and the evaluation pipeline that tells you when it’s failing.”
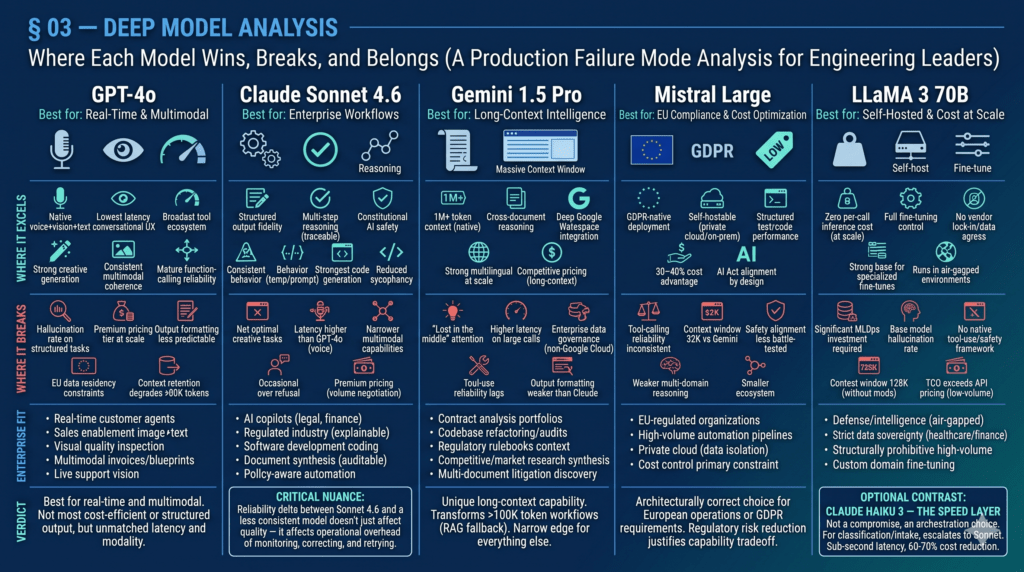
03 — DEEP MODEL ANALYSIS
Where Each Model Wins, Breaks, and Belongs
What follows is not a feature list. It is a production failure mode analysis — written for the engineering leader who needs to make defensible architecture decisions, not the analyst writing a vendor comparison slide.
| GPT-4o · OpenAI · Multimodal Flagship Best for: Real-Time & Multimodal | ||
| GPT-4o is OpenAI’s unified multimodal architecture — the model that processes voice, vision, and text in a single context window without modality-switching overhead. It remains the strongest choice when interaction speed and sensory breadth are the primary constraints. | ||
| WHERE IT EXCELS Native voice + vision + text in one unified inference call Lowest perceived latency for real-time, conversational UX Broadest tool and plugin ecosystem in the market Strong creative and open-ended generation quality Consistent multimodal coherence across sensory inputs Mature function-calling reliability for agentic tool use | WHERE IT BREAKS Hallucination rate climbs on long-form structured tasks Premium pricing tier doesn’t scale for high-volume, low-complexity ops Output formatting less predictable under strict template constraints EU data residency constraints for regulated industries Context retention degrades beyond ~80K tokens in long conversations | ENTERPRISE FIT Real-time customer-facing AI agents and voice interfaces Sales enablement copilots requiring image + text analysis Visual quality inspection in manufacturingMultimodal document processing (invoices, blueprints) AI-powered live support with vision capabilities |
| Verdict: GPT-4o is the best model for use cases where real-time interaction and multimodal coherence are the primary requirements. It is not the most cost-efficient, and it is not the most reliable for strict structured output — but nothing else combines latency, modality breadth, and ecosystem depth at this level. | ||
| Claude Sonnet 4.6 · Anthropic · Reasoning & Enterprise Reliability Best for: Enterprise Workflows | ||
| Claude Sonnet 4.6 is Anthropic’s flagship production model — positioned at the intersection of frontier reasoning capability and enterprise-grade reliability. It isn’t the model with the longest context or the fastest latency. It is the model most likely to behave consistently at the 10,000th call the way it behaved at the first. | ||
| WHERE IT EXCELS Structured output fidelity — schema adherence under strict templates across long runs Multi-step reasoning with transparent, traceable logic chains Constitutional AI safety layer reduces compliance risk significantly Refuses ambiguous or harmful tasks without catastrophic failure modes Behaviorally consistent across temperature ranges and prompt variants Strongest model for code generation with audit-trail reasoning Reduced sycophancy — less likely to agree with incorrect premises | WHERE IT BREAKS Not optimal for pure creative or free-form generation tasks Latency profile is higher than GPT-4o in real-time voice scenarios Multimodal capabilities remain narrower than GPT-4o’s unified architecture Occasional over-refusal in edge-case enterprise content domains Premium pricing requires volume-tier negotiation for high-throughput use | ENTERPRISE FIT AI copilots for legal, finance, compliance, and clinical workflows Regulated-industry deployments requiring explainable reasoning Vibe coding and AI-assisted software development Document synthesis requiring structured, auditable output Policy-aware automation where over-triggering carries legal risk |
| Verdict: Claude Sonnet 4.6 is not “smarter” than GPT-4o in any universal sense. It is more reliable for the specific category of tasks that define enterprise AI workflows: structured reasoning, consistent output formatting, and safe behavior under adversarial inputs. Reliability compounds — and in production, that compounding becomes a structural moat. | ||
| CRITICAL NUANCE Sonnet 4.6 is not “better” — it is more reliable for the specific characteristics that compound over time in enterprise environments: output consistency, schema adherence, safety behavior, and reduced sycophancy. In a 10M-call production pipeline, the reliability delta between Sonnet 4.6 and a less consistent model doesn’t just affect quality — it affects the operational overhead of monitoring, correcting, and retrying failures. |
| Gemini 1.5 Pro · Google DeepMind · Long-Context Specialist Best for: Long-Context Intelligence | ||
| Gemini 1.5 Pro’s architectural claim to fame is its native 1M+ token context window — and for a specific class of enterprise problem, it is genuinely transformative. No other production-grade model currently processes an entire contract library, codebase, or regulatory document corpus in a single inference context without chunking. | ||
| WHERE IT EXCELS 1M+ token context window — native, not chunked, not approximated Cross-document reasoning over entire codebases or contract portfolios Deep Google Workspace and Cloud integration (Drive, BigQuery, Vertex) Strong multilingual performance at scale across 100+ languages Competitive pricing for long-context workloads vs. chunked alternatives | WHERE IT BREAKS “Lost in the middle” — documented attention degradation at the core of very long contexts Higher latency on large-context calls vs. shorter-context alternatives Enterprise data governance murky for deployments outside Google Cloud Tool-use reliability lags behind GPT-4o and Claude on complex chains Output formatting consistency weaker than Claude under strict schema constraints | ENTERPRISE FIT Contract analysis across entire legal portfolios in a single call Codebase-level refactoring, security audit, and documentation Regulatory document intelligence (entire rulebooks in context) Long-form competitive and market research synthesis Multi-document discovery in litigation support |
| Verdict: Gemini 1.5 Pro has a genuinely unique capability that no other model in this comparison set matches. If your enterprise use case involves processing documents or codebases that exceed 100K tokens, and you’re currently solving it with chunking + RAG, Gemini 1.5 Pro is worth a direct architectural evaluation. For everything else, its edge narrows quickly. | ||
| Mistral Large · Mistral AI · European Sovereignty & Cost Efficiency Best for: EU Compliance & Cost Optimization | ||
| Mistral Large is the model that the GDPR and EU AI Act compliance conversation has been waiting for. Built by a European team, designed with European data sovereignty as a first-class architectural constraint, and priced at a 30–40% discount to OpenAI and Anthropic at scale, it occupies a specific and defensible niche. | ||
| WHERE IT EXCELS GDPR-native deployment architecture with EU data residency guarantees Self-hostable on private cloud or on-premise infrastructure Strong performance on structured text, code, and classification tasks 30–40% cost advantage over OpenAI and Anthropic at volume AI Act alignment by design — reduces regulatory approval friction | WHERE IT BREAKS Tool-calling reliability is inconsistent on complex multi-step agentic chains Context window limited to 32K tokens vs. Gemini’s 1M+ Safety alignment less battle-tested than Anthropic or OpenAI in adversarial settings Weaker on nuanced multi-domain reasoning tasks requiring deep cross-referencing Smaller ecosystem of integrations and third-party tooling | ENTERPRISE FIT EU-regulated organizations navigating GDPR and the AI Act High-volume, lower-complexity automation pipelines Private cloud deployments requiring strict data isolation Organizations building in-house AI capability with cost control as primary constraint |
| Verdict: If your organization operates primarily in Europe — or if you have a data protection officer who needs to sign off on AI deployment — Mistral Large is not a compromise. It is the architecturally correct choice. At equivalent cost envelopes, the regulatory risk reduction alone justifies the capability tradeoff for many enterprise workflows. | ||
| LLaMA 3 70B · Meta AI · Open-Weight Self-Hosted Best for: Self-Hosted & Cost at Scale | ||
| LLaMA 3 70B is not a product — it’s an architecture. Meta releases the weights; your team runs the infrastructure. For organizations with the MLOps capability to operate self-hosted inference, LLaMA 3 70B changes the economics of AI at scale by orders of magnitude. | ||
| WHERE IT EXCELS Zero per-call inference cost at self-hosted scale Full fine-tuning control over domain-specific behavior and output format No vendor lock-in, no data egress, no API dependency Strong base for specialized vertical fine-tunes (legal NLP, medical coding) Runs in air-gapped environments with zero external data transmission | WHERE IT BREAKS Requires significant MLOps investment to operate reliably at production scale Base model hallucination rate requires custom RLHF to reach production quality No native tool-use framework or safety alignment layer out of the box Context window limited to 128K without architectural modifications Total infrastructure cost exceeds API pricing for low-volume deployments | ENTERPRISE FIT Defense, intelligence, and public sector (air-gapped requirements) Healthcare and financial orgs with strict data sovereignty mandates High-volume pipelines where API cost becomes structurally prohibitive Custom domain fine-tuning where general-purpose model behavior is insufficient |
| Verdict: LLaMA 3 70B is a strategic infrastructure bet, not a model choice. Enterprises that invest in the MLOps capability to run it well gain permanent cost leverage and full control over model behavior. The calculus tips clearly in favor of self-hosted at volumes above roughly 20M tokens per month. | ||
| OPTIONAL CONTRAST: CLAUDE HAIKU 3 — THE SPEED LAYER Where Sonnet 4.6 is the reasoning workhorse, Claude Haiku 3 is the throughput engine. Sub-second latency, 60–70% cost reduction versus Sonnet 4.6, and sufficient accuracy for classification, triage, and intake tasks. In a well-designed multi-model architecture, Haiku handles the high-volume first-pass and escalates to Sonnet when complexity demands it. That’s not a compromise — that’s orchestration. |
04 — ENTERPRISE DECISION MATRIX
Match the Constraint to the Model
The matrix below maps enterprise use cases to optimal models — not by leaderboard score, but by which model’s architecture aligns with the real constraints of each scenario.
| Use Case | Primary Model | Secondary | Decision Rationale |
| AI Copilot — Legal / Finance / Compliance | Claude Sonnet 4.6 | Claude Haiku 3 | Constitutional safety + structured output reliability + auditable reasoning chains. |
| Real-Time Customer Interaction | GPT-4o | Claude Haiku 3 | Best-in-class latency, native multimodal (voice + text + vision) in one response. |
| Long Document Intelligence (>100K tokens) | Gemini 1.5 Pro | Claude Sonnet 4.6 | Only model with native 1M+ token context. No chunking required. |
| Vibe Coding / AI Dev Workflows | Claude Sonnet 4.6 | GPT-4o | Code correctness, reasoning transparency, lowest hallucination rate on programming tasks. |
| High-Volume Automation (>10M calls/month) | LLaMA 3 70B | Mistral Large | Self-hosting eliminates per-call cost. Fine-tuning locks in domain accuracy. |
| EU-Regulated Deployments | Mistral Large | LLaMA 3 70B | GDPR-native data residency, on-premise option, AI Act aligned by design. |
| Knowledge Retrieval / RAG Pipelines | Multi-model | — | Haiku for scoring, Sonnet for synthesis, Gemini for cross-doc joins exceeding context limits. |
| Customer Support Automation | Claude Haiku 3 | Claude Sonnet 4.6 | Sub-second intake triage, 60–70% cost reduction vs. single-model Sonnet pipeline. |
| Air-Gapped / Secure Environments | LLaMA 3 70B | Mistral Large | Self-hosted with zero external data egress. Required for defense and high-security orgs. |
| Document Intelligence — Contract Extraction | Gemini 1.5 Pro | Claude Sonnet 4.6 | Gemini ingests full corpus; Sonnet structures the extraction and flags risk. |
| ARCHITECT’S NOTE The “Primary Model” column above assumes a single-model deployment. In a properly designed multi-model architecture, most of these use cases involve two or more models operating in different layers. The primary model handles the highest-complexity step; the routing layer determines what reaches it. |
05 — COST VS. PERFORMANCE
The Tradeoff Nobody Shows You
Standard benchmarks measure capability at optimal conditions. Enterprise deployments run at scale, under latency constraints, with variable prompt complexity. The tradeoff profile looks very different in production.
* Indicative scores normalized across internal evaluation tasks. Always validate API pricing against current vendor pages.
The Real Cost Equation
Retry and error handling costs — A model that hallucinates 3% of the time in a 10M-call pipeline generates 300,000 erroneous outputs requiring human review or downstream correction. The engineering and operational cost of those errors frequently exceeds the API cost differential between a reliable and unreliable model.
The routing dividend — A properly designed routing layer — Haiku 3 for intake, Sonnet 4.6 for reasoning, Gemini for long-context — reduces average cost per query by 30–50% while maintaining or improving output quality. The routing layer doesn’t cost you money. It saves it.
| The most expensive AI architecture is the one that routes all enterprise traffic through a single premium model. Not because the model is bad — but because it’s being paid premium rates to handle tasks that a cost-efficient model could complete with equivalent quality. |
06 — REAL-WORLD USE CASE MAPPING
Five Enterprise AI Patterns, Mapped
Abstract model comparisons are useful for framing. What actually matters is how these models perform inside the specific workflow patterns that enterprise AI teams are building in 2026.
1. AI Copilots (Legal / Finance / HR / Clinical)
Model stack: Claude Haiku 3 → intake · Claude Sonnet 4.6 → reasoning · GPT-4o → multimodal
Copilots for regulated functions require reliable structured output, explainable reasoning, and consistent behavior under adversarial user inputs. Sonnet 4.6 handles reasoning and synthesis. Haiku 3 manages triage and classification at volume. GPT-4o handles any multimodal requests. The routing layer decides which model receives which turn — invisible to the user, essential to the cost profile.
2. Vibe Coding / AI-Assisted Engineering
Model stack: Claude Sonnet 4.6 → primary · GPT-4o → creative generation
AI-driven vibe coding development workflows require a model that reasons transparently about code structure, refuses to affirm incorrect premises, and produces consistent output across repeated calls. Claude Sonnet 4.6 is the current benchmark for these workflows, with lower hallucination rates on code reasoning tasks. GPT-4o adds value for front-end and UI generation where creative variance is acceptable.
3. Customer Support Automation
Model stack: Claude Haiku 3 → triage & classify · Claude Sonnet 4.6 → complex resolution · GPT-4o → voice escalation
Most customer support queries are binary — and don’t require a frontier model. Haiku 3 classifies intent, resolves simple FAQs, and routes complex cases to Sonnet 4.6 in under 800ms. GPT-4o handles live voice escalations. The result is a 60–70% cost reduction vs. a single-model architecture, with equal or better resolution rates on benchmarked support scenarios.
4. Knowledge Retrieval / RAG Pipelines
Model stack: Claude Haiku 3 → retrieval ranking · Gemini 1.5 Pro → long-context join · Claude Sonnet 4.6 → synthesis
Modern RAG pipelines have three distinct computational requirements: fast relevance scoring, context aggregation across multiple retrieved chunks, and high-quality natural language synthesis. Different models are optimal for each step. The multi-model RAG pattern typically improves answer quality by 20–35% on internal evaluations while reducing per-query cost.
5. Document Intelligence — Contract Analysis
Model stack: Gemini 1.5 Pro → full-corpus ingestion · Claude Sonnet 4.6 → structured extraction
Contract analysis and M&A due diligence involve processing documents that exceed the context windows of most models. Gemini 1.5 Pro ingests the full corpus and identifies relevant sections. Claude Sonnet 4.6 then performs structured extraction, clause comparison, and risk-flagging. The pipeline approach beats single-model chunking on both accuracy and cost.
07 — DECISION FRAMEWORK
Which Model Should You Start With?
If you are new to enterprise LLM deployment or evaluating a change to your current architecture, the following framework maps your primary constraint to a starting model recommendation.
Is regulatory compliance or data sovereignty your hard constraint?
- EU-regulated / GDPR-constrained → Start with Mistral Large. Self-hostable, EU data residency, AI Act aligned. Add LLaMA 3 70B for air-gapped layers or extremely high-volume pipelines.
- Air-gapped / defense / classified environments → LLaMA 3 70B. Self-hosted with zero external data egress. Budget 3–6 months for infrastructure maturation before production readiness.
Is real-time user interaction your primary use case?
- Real-time multimodal → GPT-4o. Lowest latency, native voice + vision + text. Use Claude Haiku 3 as cost-optimized fallback for simple conversational turns.
Are you processing documents exceeding 100K tokens?
- Long-context document intelligence → Gemini 1.5 Pro. 1M+ token native context, no chunking. Pair with Claude Sonnet 4.6 for synthesis. Evaluate for “lost in the middle” degradation on your specific document types.
Is your workflow compliance-sensitive?
- Regulated AI workflows → Claude Sonnet 4.6. Constitutional AI safety, auditable reasoning chains, structured output reliability, and measurably lower sycophancy. Use Claude Haiku 3 for intake and triage to protect the cost profile.
Is cost optimization at scale the dominant constraint?
- At >10M tokens/month → LLaMA 3 70B + Mistral Large. Self-hosted LLaMA changes the unit economics permanently. Mistral Large as managed API bridge while MLOps matures.
- API-based cost optimization → Build a routing layer. Haiku 3 for <70% complexity queries, Sonnet 4.6 for high-reasoning tasks. Achieves 35–50% cost reduction vs. single-model Sonnet.
General enterprise AI with unclear primary constraint?
- Start with Claude Sonnet 4.6. Design the model layer to be swappable from day one. The first 90 days of production data will tell you exactly which workloads need a different model.
08 — CRITICAL INSIGHT
The Real Competitive Edge: Multi-Model Orchestration
No single model wins. That’s not a hedge — it’s an architectural truth. The question is not which model is best. It’s which model is best for this specific task, at this specific cost point, with this specific latency budget, inside this specific compliance envelope.
The Four Pillars of Enterprise AI Architecture
| 01 The Routing Layer A lightweight classifier evaluates incoming queries on complexity score, domain classification, latency budget, and cost envelope — then dispatches to the appropriate model. Build it right and the system self-optimizes as model pricing changes, as new models emerge, and as your production data reveals which queries genuinely need a frontier model. | 02 Evaluation Pipelines Continuous model evaluation isn’t optional at enterprise scale. Output quality, hallucination rate, latency drift, format adherence, and safety compliance need live monitoring — not quarterly manual reviews. Build evaluation infrastructure into the architecture from day one. It also becomes the mechanism that tells you when to rotate models as the frontier shifts. |
| 03 Model Portability Every enterprise AI system built in 2026 should be designed to swap models without rebuilding the application layer. OpenAI will update GPT-4o. Anthropic will release Sonnet 4.7. Your architecture shouldn’t require a six-week engineering sprint every time the frontier moves. Model-agnostic scaffolding is a risk reduction, not a technical nicety. | 04 Why Sonnet 4.6 Is Not “Better” — But Often Right Claude Sonnet 4.6 doesn’t win on every benchmark. It wins on the specific characteristics that compound over time in enterprise environments: output consistency, schema adherence, safety behavior, and reduced sycophancy. In a 10M-call production pipeline, the reliability delta doesn’t just affect quality — it affects the operational overhead of monitoring, correcting, and retrying failures. |
09 — WHAT’S NEXT
Agents, Smaller Models, and the Evaluation Era
The model comparison conversation will continue to evolve rapidly. Here are the three structural shifts that will define enterprise AI architecture decisions in the 2026–2028 window — and how to position for them now.
1. Smaller, Domain-Specialized Models Displace Generalists
The 2026–2028 wave is fine-tuned vertical models at 7B–13B parameters outperforming frontier generalists on narrow tasks at 10–15% of the inference cost. Legal NLP, medical coding, financial extraction, and regulatory compliance are the first verticals seeing this shift. Enterprises investing in fine-tuning infrastructure and proprietary training data curation now will have a 12–18 month architectural lead.
2. Agents Replace Single Inference Calls as the Unit of Value
The unit of enterprise AI value is shifting from “answer per query” to “goal completion per workflow.” Agentic pipelines — autonomous, tool-using, multi-step systems that complete business objectives with minimal human intervention — are where the next major productivity unlock lives. Designing enterprise AI architectures around single model calls is building for 2023. Agent orchestration requires model-agnostic scaffolding, robust tool-use reliability, and failure handling that doesn’t assume the model completes the task in one shot.
3. Evaluation Becomes a Core Product Function
Organizations that can measure AI output quality at production scale — in real time, across model versions, across workflow types — gain a permanent structural advantage. They can swap models confidently based on evidence, not speculation. They can detect quality regression before users do. Evaluation pipelines stop being engineering infrastructure and become a strategic product capability.
| STRATEGIC IMPLICATION The enterprise AI investment that ages best in 2026 isn’t in any specific model. It’s in the architecture layer that sits above models: the routing logic, the evaluation pipeline, the agent scaffolding, and the fine-tuning infrastructure. Those assets compound. Model choices don’t. |
10 — CLOUDHEW POV
We Don’t Help You Choose a Model. We Design Systems That Use All of Them.
CloudHew’s enterprise AI practice is built on a single architectural premise: model selection is table stakes. Architecture is the moat. The enterprises extracting the most value from AI in 2026 aren’t the ones with the most expensive model contract — they’re the ones that built the smartest system around the models they have.
We design multi-model AI systems that deploy Claude Sonnet 4.6 for reasoning and compliance workflows, GPT-4o for real-time interaction, Gemini 1.5 Pro for long-document intelligence, and Claude Haiku 3 for cost-efficient triage — all within a single orchestrated architecture with routing logic, evaluation pipelines, and model-agnostic scaffolding that survives the next generation of model releases.
Our Three Core Practice Areas
AI Copilot Development — We design and build AI copilots for legal, financial, clinical, and operational workflows — including the full model orchestration layer, evaluation pipeline, and integration with existing enterprise systems. Not demos. Production systems with SLAs.
Vibe Coding Infrastructure — AI-assisted development environments that meaningfully accelerate engineering output. We architect the model layer, prompt engineering, and evaluation framework that makes AI-assisted vibe coding reliable enough to trust at scale.
Enterprise AI Architecture — For organizations building internal AI capability, we design the full architecture: model selection and routing, fine-tuning strategy, evaluation infrastructure, agent scaffolding, and the organizational operating model to maintain it as the frontier evolves.
| 40–60% Faster enterprise workflows | 30–50% Cost optimization vs. single-model | Day 1 Model-agnostic portability |
| Ready to build an AI system that actually delivers at scale? CloudHew designs AI Copilots, Vibe Coding environments, and multi-model orchestration platforms that deliver measurable enterprise outcomes — not proof-of-concept prototypes that stall in production. |
Get Started: cloudhew.com/services/ai-copilot-development/
“The model you choose matters less than the system you build.”
Agentic workflows shift the focus from a single “answer per query” to “goal completion” across multi-step systems. By using model-agnostic scaffolding, these systems use different LLMs to autonomously handle tool-use and failure handling, which is the next major productivity unlock for the enterprise.
For EU-regulated organizations, Mistral Large is the architecturally correct choice due to its GDPR-native deployment and data residency guarantees. It reduces regulatory approval friction compared to non-European providers.
Vibe Coding refers to AI-assisted software development where natural language drives the engineering process. Claude Sonnet 4.6 is currently the top choice for these workflows due to its superior code correctness, reasoning transparency, and low hallucination rates.
The key is Model Portability. Your architecture should use model-agnostic scaffolding to allow your team to swap out GPT-4o for a newer version or a different provider (like Anthropic or Meta) without rebuilding the entire application layer.
Modern RAG pipelines now separate tasks: Claude Haiku 3 handles fast retrieval ranking, Gemini 1.5 Pro manages long-context joins across massive datasets, and Sonnet 4.6 performs final synthesis. This specialized approach improves answer quality by up to 35%.


