

By CloudHew AI Strategy Team | Updated April 2026 | 15-min Executive Read
Executive Summary
The question is no longer whether to adopt Large Language Models — it’s how fast you can do it without losing control of cost, compliance, or quality.
The enterprise LLM market has reached $8.19 billion in 2026 and is projected to hit $71.1 billion by 2034, growing at a 26% CAGR. More telling: enterprise adoption has surged from under 5% in 2023 to over 80% today. Yet MIT research confirms that 95% of GenAI pilots fail to deliver rapid revenue acceleration — not because the technology is immature, but because the strategy is.
This guide cuts through the noise. It gives CTOs, CIOs, and product leaders a rigorous comparative framework across the four dominant enterprise LLMs — ChatGPT (OpenAI), Claude (Anthropic), Perplexity AI, and Grok (xAI) — alongside the architectural decisions, governance frameworks, and industry use cases that separate successful deployments from expensive experiments.
If you are planning your 2026 AI roadmap, you cannot afford to evaluate these tools in isolation. The competitive advantage goes to enterprises that build a deliberate, governed, multi-model strategy — and move now.
📅 Ready to assess your AI readiness? Schedule a Free AI Readiness Assessment with CloudHew →
1. Introduction: The Rise of Enterprise AI
From Novelty to Infrastructure (2022–2026)
In late 2022, ChatGPT was a curiosity. By 2024, it was a board-level topic. In 2026, it is core infrastructure. This trajectory — faster than cloud adoption, faster than mobile — has compressed what typically takes a decade into less than four years.
The driving forces are structural, not cyclical:
- Model capability has compounded faster than Moore’s Law in relative terms. The gap between a 2022 GPT-3.5 and a 2026 frontier model is not incremental — it is categorical.
- Infrastructure has matured. Cloud-based LLM deployment now accounts for 62% of enterprise deployments, driven by Azure OpenAI Service, AWS Bedrock, and Google Vertex AI.
- The talent market has shifted. Prompt engineering, RAG architecture, and LLM fine-tuning are now mainstream engineering disciplines, not arcane specialties.
- Regulatory frameworks are forming. The EU AI Act, evolving HIPAA guidance on AI, and SEC commentary on AI-generated financial disclosures are creating both constraints and clarity.
The Adoption Gap Is Widening
67% of organizations globally now use generative AI tools. But usage is not the same as value. Only 13% report enterprise-wide impact. The difference lies in architecture, governance, and change management — not in choosing the “right” model.
72% of enterprise IT leaders plan to increase LLM spending in 2026. The organizations allocating those budgets strategically — with clear use cases, governed data flows, and measurable KPIs — will pull decisively ahead of those buying licenses without a plan.
Key Insight for Decision-Makers: The window for first-mover advantage in LLM-powered operations is closing. Organizations that have already deployed production-grade LLM systems are compounding their data advantages and workflow efficiencies every quarter.
2. What Are LLMs? A Concise Technical Primer for Business Leaders
The Architecture in Plain Terms
A Large Language Model is a deep neural network trained on vast text corpora to predict, generate, and reason with language. The dominant architecture — the Transformer — was introduced by Google in 2017 and remains the foundation of every major model in production today.
Three concepts matter most to enterprise leaders:
Tokens: The atomic unit of LLM processing. A token is roughly ¾ of a word. A model’s context window — measured in tokens — determines how much information it can process in a single interaction. A 200,000-token context window can hold roughly a full legal contract, an annual report, or hours of meeting transcripts.
Fine-tuning: The process of further training a pre-trained model on domain-specific data. Fine-tuning shifts a general-purpose model toward a specific vocabulary, task type, or compliance posture. It is expensive and requires careful data governance.
Retrieval-Augmented Generation (RAG): Rather than baking knowledge into model weights through fine-tuning, RAG systems dynamically retrieve relevant documents from a knowledge base at inference time, then feed them to the model as context. This is the dominant enterprise architecture in 2026 because it keeps proprietary data outside the model while enabling highly contextual outputs.
A Framework for the Three Commonly Confused Terms
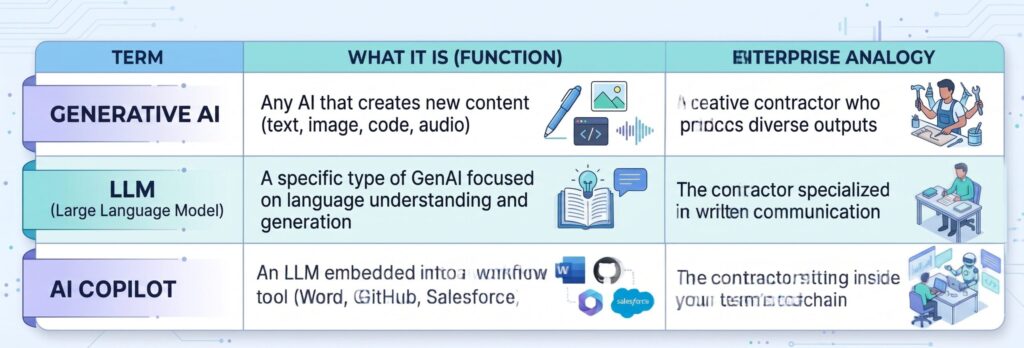
The Business Leader’s Analogy: Think of an LLM as a new hire who has read virtually everything ever written — every textbook, forum, legal filing, and research paper — but has no memory of your last conversation, no access to your internal systems (unless given it), and the occasional confident-sounding mistake. Your job, as the enterprise, is to give this hire the right context, guardrails, and feedback loops.
3. Detailed Comparative Analysis of Leading Enterprise LLMs
3.1 ChatGPT (OpenAI)
Overview: OpenAI’s flagship product family, including GPT-4o and the o-series reasoning models, remains the most widely deployed enterprise LLM by raw user count. The ChatGPT Enterprise tier and Azure OpenAI Service provide the primary enterprise access points.
Core Strengths:
- Broadest third-party integration ecosystem (plugins, GPTs, API partners)
- Strong multimodal capabilities: text, images, audio, and vision in a single model
- Advanced reasoning via the o1/o3 model family for complex analytical tasks
- Mature Azure integration makes it the default for Microsoft-stack enterprises
- Largest developer community globally; fastest time to find implementation help
Weaknesses:
- Context window (128K tokens for GPT-4o) is smaller than Claude’s offerings
- Long-document fidelity can degrade at extreme context lengths
- OpenAI’s pricing can escalate sharply at enterprise inference volume
- Anthropic and Google have closed the capability gap significantly in 2025–2026
Pricing Model: Token-based API pricing (input/output). ChatGPT Enterprise is seat-licensed. Azure OpenAI carries additional provisioned throughput costs. Organizations spending over $250,000/year should negotiate enterprise agreements directly.
Context Window: 128,000 tokens (GPT-4o); up to 200K with some o-series configurations
Multimodal Capabilities: Text, image input, image generation (via DALL-E), audio input/output (GPT-4o), vision
Enterprise Readiness: High. SOC 2 Type II, HIPAA BAA available, Azure Government cloud options, data residency controls.
Security & Compliance: ChatGPT Enterprise offers zero data retention by default. Azure OpenAI provides VNet integration, private endpoints, and comprehensive audit logging.
3.2 Claude (Anthropic)
Overview: Claude has emerged as the top enterprise LLM by market share in 2025–2026, capturing 32% of enterprise deployments compared to OpenAI’s 25% (Menlo Ventures, mid-2025). This shift reflects Claude’s superior performance on long-document tasks, coding (42% developer market share vs. OpenAI’s 21%), and its safety-first architecture that resonates with legal, healthcare, and financial services teams.
Core Strengths:
- Industry-leading context window (up to 200,000 tokens) with superior fidelity at long contexts
- Best-in-class performance on complex reasoning, nuanced writing, and code generation
- Constitutional AI training methodology produces outputs better aligned with enterprise communication standards
- Claude Code has become the dominant agentic coding tool for engineering teams
- Model Context Protocol (MCP) positions Claude as the leading agent-first architecture
Weaknesses:
- Smaller third-party ecosystem than OpenAI
- Image generation not natively supported (vision/analysis only)
- Anthropic’s enterprise sales motion is newer than OpenAI’s
Pricing Model: Token-based API pricing via Anthropic or AWS Bedrock. Claude for Enterprise is seat-licensed.
Context Window: 200,000 tokens (Claude Sonnet 4.6, Opus 4.6)
Multimodal Capabilities: Text, image input/analysis, document processing, code; no native image generation
Enterprise Readiness: High. AWS Bedrock deployment, SOC 2, HIPAA BAA available, Anthropic’s safety frameworks provide regulatory audit trails.
Security & Compliance: Strong privacy posture; Anthropic does not train on API user data by default. Enterprise-grade data isolation available through AWS Bedrock and GCP Vertex.
3.3 Perplexity AI
Overview: Perplexity AI occupies a distinct niche: it is fundamentally a search-augmented LLM platform rather than a pure generative model. It combines real-time web retrieval with LLM synthesis, making it uniquely suited for research-intensive enterprise workflows where factual currency matters.
Core Strengths:
- Real-time web retrieval eliminates knowledge cutoff limitations for research tasks
- Inline citations with source verification — critical for compliance and audit trails
- Perplexity Enterprise Pro supports internal knowledge base integration
- Exceptional for competitive intelligence, market research, and regulatory monitoring workflows
- Significantly lower hallucination rates on factual queries vs. non-RAG models
Weaknesses:
- Not a foundational model — relies on underlying LLMs (GPT-4, Claude, etc.) for generation
- Less suited for creative, long-form generation, or complex code tasks
- Context window and customization options are more limited than direct API access
- Enterprise-grade fine-tuning is not available
Pricing Model: Pro subscription ($20/user/month) and Enterprise Pro (custom pricing). API access available.
Context Window: Dependent on underlying model; effective retrieval window is dynamic based on search results
Multimodal Capabilities: Text, image analysis, document upload; search-grounded outputs
Enterprise Readiness: Medium-High. SSO, team management, and data controls available in Enterprise Pro. Audit logging is maturing.
Security & Compliance: Enterprise Pro offers dedicated data controls. Best suited for research teams where data ingested is already in the public domain or internal documents uploaded under controlled conditions.
3.4 Grok (xAI)
Overview: Grok, developed by Elon Musk’s xAI, has evolved from a conversational novelty to a competitive frontier model with Grok-3 released in early 2025. Its differentiation lies in real-time X (Twitter) data integration, strong STEM reasoning, and an increasingly capable multimodal architecture.
Core Strengths:
- Real-time access to X/Twitter data stream — unmatched for social listening, trend analysis, and PR/comms use cases
- Grok-3 shows competitive performance on STEM benchmarks, particularly mathematics and scientific reasoning
- “Think” mode (extended chain-of-thought reasoning) available for complex analytical tasks
- No restrictive content policies that limit some competitor use cases
- Integrated into X Premium, reducing friction for teams already on that platform
Weaknesses:
- Enterprise tooling, compliance documentation, and SLA infrastructure significantly lag OpenAI and Anthropic
- No dedicated HIPAA BAA or formal compliance certifications as of Q1 2026
- Limited third-party integrations and API ecosystem maturity
- Data provenance concerns for regulated industries
- Organizational uncertainty around xAI’s enterprise roadmap
Pricing Model: API access through xAI; X Premium integration at consumer tier. Enterprise pricing is custom and less transparent than competitors.
Context Window: 131,072 tokens (Grok-3)
Multimodal Capabilities: Text, image input, image generation (Aurora), voice
Enterprise Readiness: Low-Medium. Suitable for specific unregulated use cases (content, marketing, research). Not recommended for regulated verticals (healthcare, finance, legal) in current form.
Security & Compliance: Compliance framework is nascent. Data handling policies are less mature than OpenAI or Anthropic.
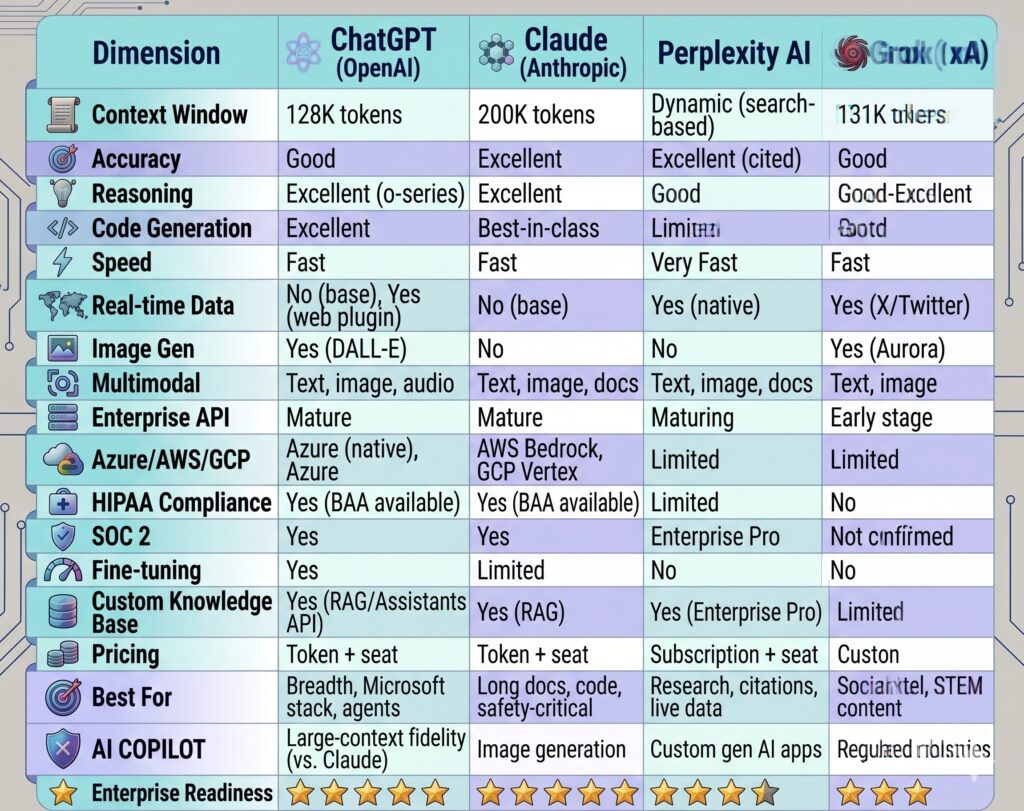
4. Enterprise LLM Comparison Table
5. Enterprise Use Cases by Industry
5.1 Healthcare
The Opportunity: Healthcare generates over 30% of the world’s data, yet 97% of it remains unanalyzed. LLMs are closing this gap at speed.
Use Cases:
- Clinical Documentation Automation: LLMs transcribe, structure, and code physician-patient interactions in real time, reducing documentation burden by 30–40% per clinician (per NEJM Catalyst data). Models: Claude (long-context, HIPAA-compliant), ChatGPT (Azure OpenAI with HIPAA BAA).
- Prior Authorization Acceleration: Generative AI extracts clinical criteria, matches against payer policies, and drafts authorization letters — cutting processing time from days to minutes.
- Medical Literature Synthesis: Perplexity AI with internal knowledge base integration enables clinicians to synthesize research across thousands of papers with cited outputs.
- Patient Communication: LLM-generated personalized discharge instructions, medication reminders, and care plan summaries in patients’ native languages.
ROI Impact: Leading health systems report 25–45% reduction in administrative overhead for clinical teams. At $150K+ fully-loaded cost per clinician, even 10% time recovery represents material margin improvement.
Implementation Complexity: High. HIPAA BAA requirements, EHR integration (Epic, Cerner), de-identification pipelines, and clinical validation workflows must all be addressed before production deployment.
💡 CloudHew Insight: Healthcare LLM implementations require a dedicated AI governance layer before any patient-adjacent deployment. Our healthcare AI practice builds compliant RAG architectures that keep PHI out of model training while enabling clinical intelligence at scale. Talk to our Healthcare AI team →
5.2 Financial Services
The Opportunity: Financial services firms face a unique dual pressure: massive document volumes (contracts, filings, research) and stringent regulatory exposure. LLMs address both simultaneously.
Use Cases:
- Regulatory Document Analysis: LLMs extract obligations, flag deviations, and generate compliance summaries from Basel III frameworks, DORA requirements, or SEC filings — reducing analyst time by 60–70% on document review tasks.
- Earnings Call Intelligence: Real-time transcription and sentiment analysis of earnings calls, with automatic extraction of forward guidance, risk factors, and management tone shifts.
- Credit Memo and Underwriting Automation: LLMs synthesize financial statements, industry data, and borrower history into structured credit analysis frameworks.
- Fraud Narrative Analysis: Combining LLMs with structured transaction data to identify anomalous patterns in fraud investigation narratives.
- Client Reporting Personalization: Automated generation of personalized investment commentary at scale, reviewed by advisors before delivery.
ROI Impact: Investment banks using LLMs for research synthesis report 50–70% reduction in analyst time on first-draft production. Private equity firms cite 3–5x faster due diligence on comparable companies.
Implementation Complexity: Medium-High. Data residency requirements, SEC Rule 17a-4 retention compliance, and model explainability for credit decisions require careful architecture.
5.3 Retail & E-Commerce
The Opportunity: Retail operates at a scale where personalization was previously impossible. LLMs change the economics of 1:1 customer experiences.
Use Cases:
- Dynamic Product Description Generation: LLMs generate SEO-optimized, tone-consistent product descriptions at catalogue scale — eliminating what was previously a massive content operations burden.
- AI-Powered Customer Support: LLMs resolve 60–70% of customer queries without human escalation, with context awareness across purchase history, returns, and prior interactions.
- Personalized Email & Campaign Copy: Segment-level personalization at individual scale, with A/B test generation and performance optimization loops.
- Inventory Demand Forecasting Narrative: LLMs translate quantitative forecasting outputs into plain-language procurement recommendations for buyers.
- Return Reason Analysis: Structured extraction from unstructured return notes to identify product quality issues at scale.
ROI Impact: Leading e-commerce players report 20–35% uplift in email conversion rates from LLM-personalized copy, and 40–60% reduction in support cost-per-contact with LLM-first routing.
Implementation Complexity: Low-Medium. Retail has the advantage of relatively unstructured data environments; fewer compliance constraints than healthcare or finance.
5.4 SaaS & Technology
The Opportunity: Technology companies are simultaneously the largest LLM consumers and the fastest to embed AI into their products. The competitive pressure here is the most acute.
Use Cases:
- AI-Powered Developer Tooling: Claude Code and GitHub Copilot (GPT-4 powered) are driving 20–40% productivity improvements in engineering teams that measure them rigorously.
- Automated QA and Test Generation: LLMs generate comprehensive test suites from functional specifications, dramatically reducing regression coverage gaps.
- Technical Documentation: Auto-generated API documentation, changelog summaries, and onboarding guides that stay current with code changes.
- Customer Success Intelligence: Synthesis of support tickets, product telemetry, and NPS responses to identify churn risk and expansion opportunity.
- Internal Knowledge Management: LLM-powered enterprise search across Confluence, Notion, Slack, and internal wikis — replacing keyword search with semantic understanding.
ROI Impact: SaaS companies embedding LLMs in their products report 15–30% improvement in feature adoption and 25% reduction in time-to-onboard for new users.
Implementation Complexity: Low-Medium for internal tooling; Medium-High for product embedding (requires evaluation, safety testing, and customer-facing SLAs).
5.5 Manufacturing
The Opportunity: Manufacturing’s digital transformation has largely been hardware-first. LLMs are unlocking the intelligence layer on top of that infrastructure.
Use Cases:
- Maintenance Documentation Intelligence: LLMs parse thousands of pages of OEM manuals, historical maintenance logs, and sensor telemetry to generate context-aware repair procedures.
- Quality Control Report Synthesis: Automated extraction of defect patterns from unstructured QC notes and inspection reports.
- Supply Chain Risk Narration: LLMs synthesize news feeds, supplier financials, and logistics data into natural-language risk briefings for procurement teams.
- Safety Incident Analysis: Structured extraction from incident reports to identify systemic risk factors across facilities.
- RFQ and Procurement Drafting: LLMs generate first-draft Request for Quotation documents from engineering specifications.
ROI Impact: Early adopters in discrete manufacturing report 30–50% reduction in time-to-resolution for maintenance events and 20% improvement in procurement cycle time.
Implementation Complexity: High. Legacy system integration (SCADA, ERP, MES), connectivity constraints on plant floors, and safety-critical validation requirements create significant deployment overhead.
6. LLM Architecture in Enterprise Environments
Building a production-grade LLM system is not a model selection decision. It is an architectural discipline. The following components must be designed deliberately.
Retrieval-Augmented Generation (RAG)
RAG is the dominant enterprise LLM architecture pattern in 2026, and for good reason. Rather than attempting to encode all organizational knowledge into model weights (which requires expensive fine-tuning and creates data governance nightmares), RAG systems:
- Store proprietary documents in a vector database (Pinecone, Weaviate, pgvector, Azure AI Search)
- At query time, convert the user’s question into a vector embedding
- Retrieve the semantically most similar documents from the knowledge base
- Inject those documents into the LLM prompt as context
- Generate a response grounded in retrieved content
The result: a system that “knows” your organization’s specific data without that data ever touching model training infrastructure.
RAG implementations reduce hallucination rates by 60–80% compared to ungrounded LLM responses on domain-specific queries. This is the single most important quality improvement available to enterprise deployers.
Fine-tuning vs. Prompt Engineering
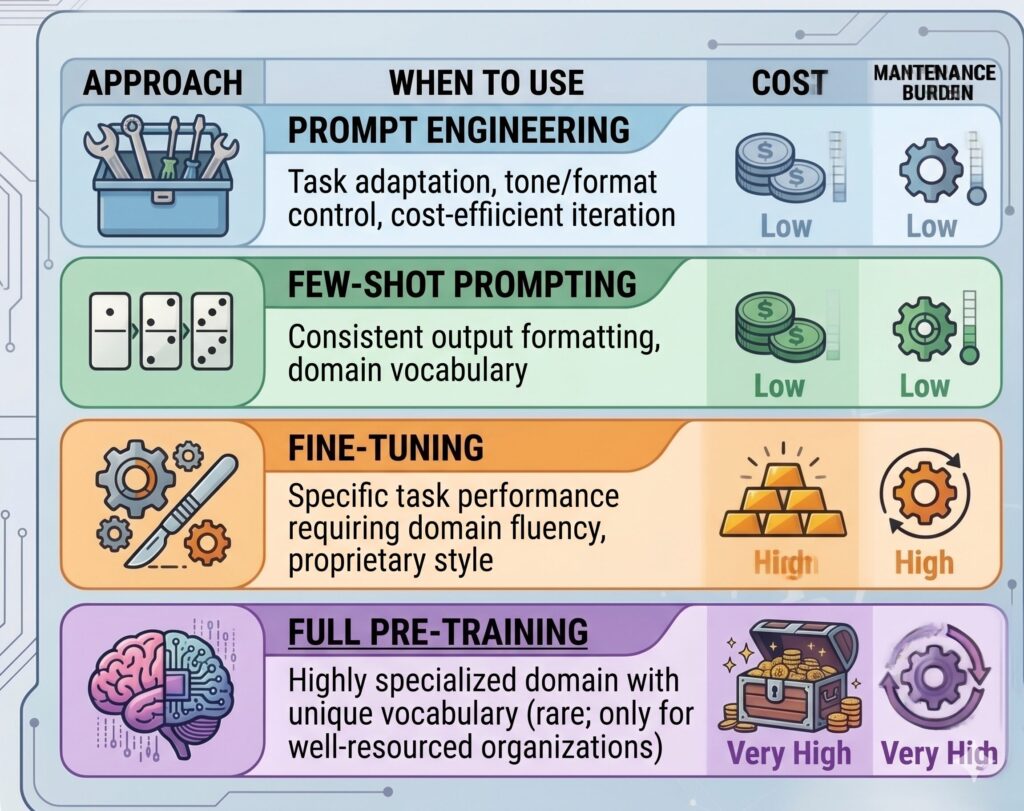
CloudHew Recommendation: For 90% of enterprise use cases, a well-designed RAG architecture with systematic prompt engineering delivers superior ROI compared to fine-tuning. Fine-tuning is appropriate for narrow, high-volume, latency-sensitive tasks where prompt context is insufficient.
API Orchestration
Multi-model enterprise architectures require an orchestration layer that routes queries to the appropriate model based on task type, cost, latency requirements, and context. Frameworks including LangChain, LlamaIndex, and Anthropic’s MCP have become production standards. 37% of enterprises already run 5 or more LLM models simultaneously in production.
Security Architecture
A robust enterprise LLM security posture includes:
- Input/output filtering: Guardrail layers (Guardrails AI, LLM Guard) that screen both incoming prompts and outgoing responses
- PII detection and redaction: Automated identification and removal of sensitive data before it reaches model APIs
- Audit logging: Complete traceability of every LLM interaction for compliance and forensics
- Role-based access control (RBAC): Ensuring LLM capabilities are scoped to appropriate organizational roles
- Data residency enforcement: Ensuring model API calls stay within defined geographic boundaries
7. Risks, Challenges & Governance
Understanding the risk landscape is not optional — it is the prerequisite to any responsible LLM deployment.
Hallucination Risk
LLMs can generate plausible-sounding false information with high apparent confidence. In regulated environments, a hallucinated legal citation, incorrect drug interaction, or fabricated financial figure can carry serious liability. Stanford HAI estimates hallucinations occur in 30–40% of ungrounded LLM outputs. RAG architectures with source attribution (like those Perplexity uses natively) are the primary mitigation; human-in-the-loop review remains necessary for high-stakes outputs.
Data Privacy
Every prompt sent to an external LLM API is a potential data exposure event. Enterprises must audit what data their employees are inputting, and under what terms it is processed. Key questions: Does the provider train on your API data? Where is it processed and stored? Can you obtain a Data Processing Agreement (DPA)?
Compliance Requirements
- GDPR: Any LLM processing data about EU residents requires a lawful basis, a DPA with the model provider, and mechanisms for data subject rights (access, deletion). Cross-border data transfers require standard contractual clauses or equivalent mechanisms.
- HIPAA: Protected Health Information (PHI) requires a signed Business Associate Agreement (BAA) with the model provider. As of 2026, OpenAI (via Azure) and Anthropic offer BAAs; Grok does not.
- SEC/FINRA: AI-generated financial communications carry the same regulatory obligations as human-generated ones. Model outputs in client-facing contexts require the same review and retention policies.
- EU AI Act: High-risk AI systems (those impacting employment, credit, health) face mandatory conformity assessments, transparency requirements, and human oversight obligations from 2025 onwards.
Shadow AI Risk
Gartner estimates that 40% of enterprise LLM usage in 2025 is unmanaged — employees using personal ChatGPT accounts or consumer tools to process corporate data, completely outside IT governance. Shadow AI represents a data leakage risk that security teams often do not detect until after an incident.
Cost Management
LLM costs are highly non-linear. A pilot running 100 queries per day scales to 100,000 queries per day, and the cost economics change dramatically. Token consumption, model selection, caching strategy, and retrieval efficiency all need to be engineered for cost at scale — not as an afterthought.
🔒 Enterprise Governance Gap? CloudHew builds AI governance frameworks that cover policy, technical controls, and compliance documentation. Download our Enterprise AI Governance Checklist →
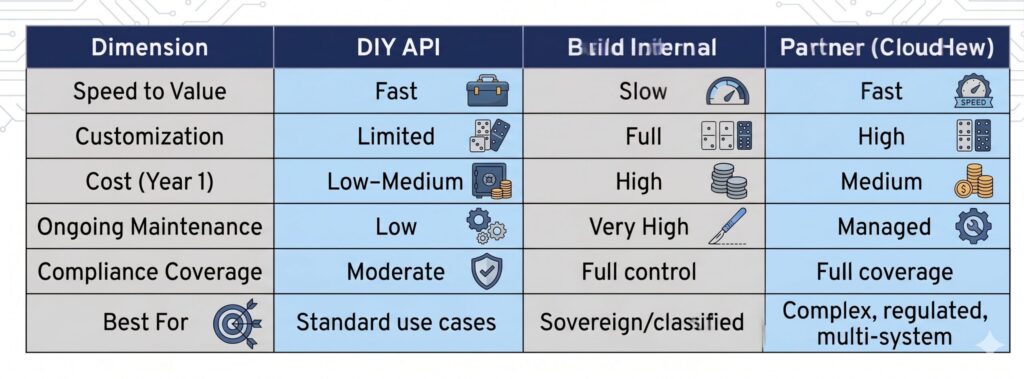
8. The Build vs. Buy vs. Partner Decision Framework
One of the highest-stakes architectural decisions an enterprise faces is how to source its LLM capability. Here is a structured framework:
Use OpenAI / Anthropic / Perplexity APIs Directly When:
- Your use case is well-defined and low-sensitivity (marketing, internal productivity)
- Speed to market is the primary constraint
- Internal AI engineering capacity is limited
- The use case does not require model customization
- You need proven compliance infrastructure quickly
Build Internal AI Infrastructure When:
- Your data is sufficiently sensitive that no third-party processing is acceptable (intelligence, defense, highly proprietary IP)
- You have the engineering capacity to maintain open-source model infrastructure (Llama, Mistral)
- Your query volume makes API pricing economically unviable at scale
- You require full model customization and fine-tuning control
Partner with a Specialized AI Consultancy (like CloudHew) When:
- You have strategic use cases but lack the internal expertise to architect, govern, and scale them
- You need to compress 18 months of AI learning into a 90-day deployment cycle
- Your implementation spans multiple models, data systems, and compliance requirements
- You need ongoing model management, optimization, and governance — not a one-time build
- Your industry has specific regulatory requirements that require experienced interpretation
9. The Future of LLMs: 2026–2030 Predictions
Autonomous AI Agents Will Become Standard Infrastructure
The 2025 “year of agents” (Menlo Ventures) has given way to production deployment. By 2027–2028, the majority of enterprise knowledge work will be structured around human-agent collaborative workflows, not human-only or AI-only processes. Anthropic’s MCP, OpenAI’s agent frameworks, and Google’s Vertex AI agents are all racing toward the same destination: reliable, auditable AI systems that can execute multi-step tasks across enterprise software systems.
Industry-Specific LLMs Will Capture High-Value Verticals
General-purpose LLMs will remain dominant for broad use cases, but domain-specific models are growing at a 35.1% CAGR — the fastest segment in enterprise AI. Expect purpose-built LLMs for radiology, legal contract review, actuarial modeling, and industrial process optimization to reach production quality by 2027–2028.
AI Copilots in Every Enterprise Application
By 2028, a productivity suite, CRM, ERP, or communication tool that lacks an embedded AI copilot will be a competitive liability. Salesforce Einstein GPT, Microsoft Copilot 365, and SAP Joule have established the pattern. Every enterprise software vendor will follow.
Regulatory Pressure Will Create Governance-Led Procurement
The EU AI Act’s full implementation timeline runs through 2026–2027. The US is developing federal AI policy frameworks. Regulated industries will increasingly require LLM vendors to provide conformity assessments, audit trails, and explainability documentation as standard procurement criteria. This will accelerate enterprise adoption of compliance-first AI architectures.
Cost Curves Will Continue Declining
The cost of frontier model inference has dropped by approximately 10x over the past 18 months. This trend will continue, driven by model efficiency improvements, hardware optimization, and competitive pressure. The economics of LLM deployment will look fundamentally different by 2028 — making use cases that are currently marginal very attractive.
10. How CloudHew Helps Enterprises Adopt LLMs
CloudHew is an AI/GenAI consulting firm that specializes in helping enterprise organizations move from LLM strategy to production deployment — with governance, speed, and measurable ROI.
We do not sell software. We build capability. Here is how we work with enterprise clients:
AI Strategy & Readiness Assessment
Before selecting models or writing code, we help you identify the highest-ROI LLM use cases in your specific business context, assess your data readiness, and build an AI adoption roadmap that your board and legal team can stand behind. This is where the 95% failure rate gets beaten — at the strategy layer, not the implementation layer.
Custom LLM Development & RAG Architecture
Our engineers design and build production-grade LLM systems using the right combination of OpenAI, Claude, open-source, and domain-specific models for your use case. Every architecture we build includes retrieval infrastructure, output quality monitoring, and cost management by design.
Enterprise Integration
LLMs only create value when they are connected to the systems where work happens. CloudHew integrates LLM capabilities with Azure, AWS, Salesforce, SAP, Microsoft 365, and custom enterprise data platforms — so your AI investments compound with your existing technology stack.
AI Governance Frameworks
We build the policy, technical, and compliance infrastructure your organization needs to deploy AI responsibly: data classification policies, prompt audit systems, model risk management frameworks, GDPR/HIPAA compliance documentation, and employee AI use policies.
Ongoing Model Management & Optimization
The LLM landscape changes every quarter. Our managed AI services keep your deployments current — monitoring for model drift, updating prompts as model behavior evolves, and continuously optimizing cost and performance ratios.
🚀 Ready to move from AI experimentation to AI advantage?
Book a 30-Minute AI Strategy Consultation with CloudHew →
Our AI experts will assess your current state, identify your top 3 high-ROI use cases, and outline a 90-day path to production deployment.
11. Frequently Asked Questions
Q1: Which LLM is best for enterprise use in 2026?
There is no single “best” — the answer depends on your use case. For long-document analysis, code generation, and safety-critical applications, Claude (Anthropic) currently leads. For Microsoft-stack enterprises requiring broad capability and mature ecosystem integration, ChatGPT (OpenAI via Azure) is the strongest choice. For research-intensive workflows requiring real-time data with citations, Perplexity AI is purpose-built. For social intelligence and STEM-heavy content work, Grok offers unique advantages. Most mature enterprise AI practices run 2–3 models simultaneously.
Q2: Is ChatGPT secure for business use?
ChatGPT Enterprise and Azure OpenAI Service are designed for enterprise security — with zero data retention by default, SOC 2 Type II certification, and HIPAA BAA availability. The consumer ChatGPT product is not suitable for processing sensitive business data. The distinction matters: many employees using ChatGPT.com are inadvertently using the consumer product, not the enterprise-grade service.
Q3: How much does enterprise LLM implementation cost?
Costs vary dramatically by scope. A focused productivity use case (internal knowledge search, document summarization) can be deployed for $50,000–$150,000 in the first year. A production-grade, multi-use-case deployment with full governance infrastructure typically runs $250,000–$1,000,000+ for design and build, with ongoing operational costs scaling with usage volume. 37% of enterprises spend over $250,000 annually on LLMs. The ROI at that investment level, when properly architected, is typically 3–10x in the first 24 months.
Q4: How do you integrate an LLM with existing enterprise systems?
Integration architecture depends on your data sources and workflows. The most common patterns are: (1) RAG integration — connecting LLMs to existing knowledge repositories (SharePoint, Confluence, internal databases) via vector search; (2) API orchestration — embedding LLM calls into existing application workflows via LangChain, LlamaIndex, or custom middleware; (3) Copilot embedding — using native integrations like Microsoft Copilot for M365 or Salesforce Einstein for workflow-embedded AI. CloudHew specializes in all three patterns.
Q5: What is the difference between fine-tuning and RAG, and which should we use?
RAG retrieves relevant information from your documents at query time and feeds it to the LLM as context. Fine-tuning permanently adjusts the model’s weights using your training data. For the vast majority of enterprise use cases, RAG is superior: it is cheaper, faster to update, and safer from a data governance perspective. Fine-tuning is appropriate for narrow, high-volume tasks where the domain vocabulary is highly specialized and RAG latency is a constraint.
Q6: How do we handle GDPR compliance with LLMs?
GDPR compliance for LLM deployments requires: (1) a lawful basis for processing (usually legitimate interest or contractual necessity); (2) a Data Processing Agreement (DPA) with your model provider; (3) data minimization practices (avoid sending more personal data than necessary); (4) mechanisms for data subject rights (access, deletion); and (5) cross-border transfer mechanisms if using US-based providers. CloudHew includes GDPR compliance documentation as standard in all enterprise AI engagements for EU-data-handling clients.
Q7: What is Shadow AI and why does it matter?
Shadow AI refers to employees using unauthorized AI tools — typically personal ChatGPT accounts, Claude.ai personal subscriptions, or other consumer products — to process corporate data. It is estimated that 40% of enterprise LLM usage in 2025 is unmanaged. Shadow AI creates data leakage risk, compliance violations, and IP exposure that is invisible to IT and legal teams. An enterprise AI governance program that provides employees with approved, governed AI tools is the most effective Shadow AI mitigation.
Q8: How long does it take to deploy a production LLM system?
A well-scoped, focused LLM deployment (single use case, defined data sources) can reach production in 8–12 weeks with the right architecture and governance foundation in place. Broader enterprise AI programs spanning multiple use cases, data systems, and compliance requirements typically run 6–18 months for full enterprise scale. The organizations that move fastest are those who invest in AI readiness infrastructure (data governance, vector databases, API orchestration layers) once, then deploy multiple use cases on top of that foundation.
Conclusion: The Window Is Closing
In 2023, LLM experimentation was optional. In 2024, it became strategic. In 2026, it is operational reality — and the gap between AI-native enterprises and their competitors is no longer theoretical. It is measured in productivity, margin, speed, and customer experience.
The comparative analysis in this guide makes clear that no single LLM wins across all enterprise use cases. The competitive advantage goes to organizations that build a deliberate, multi-model strategy — one that matches the right tool to each task, governs data flows rigorously, and continuously optimizes for cost and quality.
The organizations losing ground are those waiting for the “right time” to start. With 80% of enterprises already deploying generative AI, and Anthropic and OpenAI adding enterprise capabilities every quarter, the baseline is moving faster than any planning cycle can track.
CloudHew exists to compress this journey. We have built AI systems in regulated and unregulated environments, across multiple industries, on every major cloud platform. We know where the 95% failure rate comes from — and we know how to avoid it.
🚀 Your Next Step with CloudHew
Stop piloting. Start compounding.
Choose your next step:
- Schedule a Free AI Readiness Assessment → — 60-minute diagnostic to identify your highest-ROI LLM use cases
- Talk to Our AI Experts → — Discuss your specific architecture, compliance, or integration challenges
- Download Our Enterprise LLM Strategy Guide → — The 40-page framework our clients use to govern and scale AI programs


